
C’est le troisième et dernier volet de mon projet de montée en débit de mon réseau interne.
Le projet initial était de remplacer mon switch de cœur de réseau par un modèle disposant de suffisamment d’interfaces 10 Gbps pour y brancher mes hyperviseurs, ainsi que le lien avec mon switch sur lequel est branchée ma freebox delta.
Pour ce faire, j’avais en ligne de mire le commutateur CRS312-4C+8XG-RM de mikrotik. Ainsi, je disposais de toutes les interfaces 10 Gbps pour brancher mon infra, et de ports supplémentaires en 1/2,5/5/10 Gbps pour brancher les différents PCs et périphériques de la maison, avec une belle évolutivité.
Malheureusement, l’indécence de l’augmentation des prix ces 18 derniers mois a mis un frein à mon délire, et j’ai du revoir mes ambitions en me rabattant sur le CRS309-1G-8S+IN, pas loin de 3 fois moins cher : ceci au prix d’une quantité moindre d’interfaces, et toutes en SFP+ au lieu d’avoir un mix interfaces cuivre/ interfaces modulaires.
La conséquence est que ce switch ne viendra pas remplacer mon cœur de réseau actuel, mais deviendra mon nouveau cœur de réseau, reléguant le précédent à un statut de switch d’accès.
Il y a également deux autres implications:
- ce switch ne disposant que d’interfaces modulaires, il faudra ajouter à la facture le prix des modules SFP+ et autres câbles DAC
- comme il vient en complément du switch qui est dans ma baie 7U au lieu de le remplacer, la consommation électrique de l’ensemble va probablement augmenter de manière significative
Du coup, après réflexion, je me demande si ce choix sera le plus économique à long terme. Quoi qu’il en soit, c’est fait, et le résultat immédiat représente probablement un beau progrès.
Positionnement du nouveau switch
Comme évoqué, c’est à présent sur ce switch que seront branchés mes deux hyperviseurs, chacun avec deux interfaces 10Gbps. Une pour l’interface d’administration, qui est également celle utilisée pour les flux du cluster (notamment les migrations de VM), et l’autre qui supporte le bridge permettant la mise en réseau des machines virtuelles.
Le lien de cascade entre ce switch et le switch qui est dans mon salon à côté de la freebox, utilise un câble en cuivre, avec un module SFP+/10G base-T de chaque côté du câble.
Enfin, le lien de cascade avec l’autre switch de la même baie, qui n’a que des interfaces 1Gbps se fait par l’interface ethernet du commutateur.

J’ai flouté la photo ci-dessus non pas pour cacher quoi que ce soit (pas même le gros bordel de câbles dans la baie), mais juste pour mettre en évidence le nouveau commut. Et non, ce n’est pas une hallucination…

…Oui, j’ai bien été contraint de bricoler un ventilo sur un câble USB, pour le poser à l’arrache sur les modules, pour les refroidir. Car les modules 10Gbps cuivre, ça chauffe beaucoup.
Trop.
Tellement qu’au bout de quelques minutes, arrivés aux alentours des 100-105°C, routerOS les éteint pour éviter le drame. Mon bricolage a été suffisant pour maintenir une température acceptable pendant la canicule cet été, mais c’est en définitive une nouvelle contrariété. J’ai acheté un switch refroidi passivement, et le premier truc que je fais avec, c’est de rajouter un ventilateur…Et bien évidemment, c’est pareil avec le module qui est à l’autre bout du câble, dans mon switch du salon.
Je ne vais pas pouvoir laisser ça tel quel, et il va bien falloir que je fasse quelque chose de plus propre, mais on verra plus tard.
L’évolution des débits dans le réseau local et internet
C’est la partie réjouissante de l’aventure.
Objectif 1 : profiter des 8Gbps de la freebox delta
Bon là, je ne me faisais pas vraiment d’illusion, et n’avais donc pas grande ambition. Comme je l’avais précédemment écrit, mon parefeu étant virtuel, je constatais déjà une charge importante sur mon hyperviseur lorsque qu’un flux à 1 Gbps traversait 2 interfaces du parefeu. A la louche, j’estimais à 2,5 Gbps ce que je pouvais espérer, compte tenu de ce que j’observais avec un flux traversant à 1Gbps.
J’ai réalisé diverses mesures depuis mon PC de jeu, branché en 10Gbps sur mon coeur de réseau.
Avec l’application speedtest pour windows :
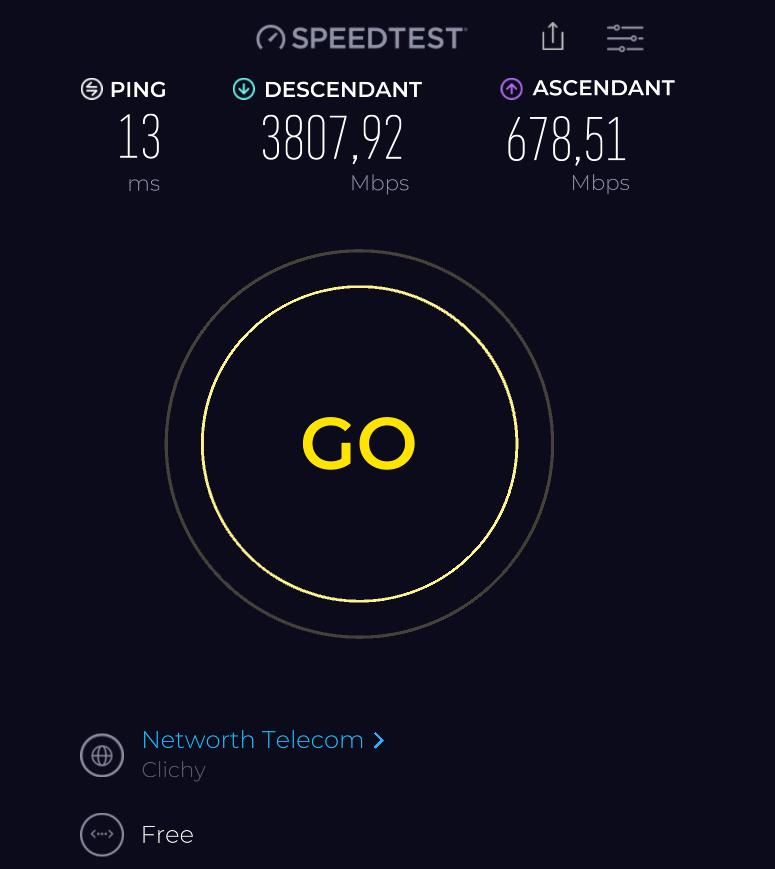
Première bonne surprise, je dépasse mon estimation pour approcher les 4Gbps en download. En upload, je remplis sans surprise le tuyau de 700 Mbps de mon abonnement freebox delta.
J’ai confirmé ce résultat avec iperf, toujours depuis le même PC, démarré cette fois-ci sous Linux:
iperf3 -c paris.testdebit.info -p 9200 -R -P 8
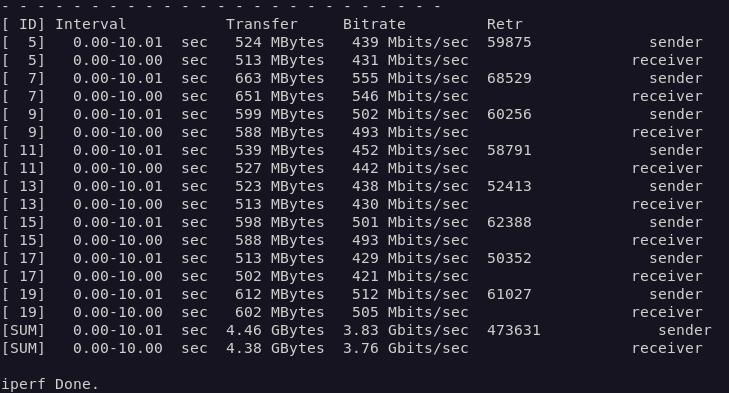
Le résultat corrobore le précédent. On remarque que la colonne Retr présente des nombres très élevés. Cette colonne représente le nombre de fois où la pile TCP a été contrainte à une retransmission du paquet concerné, car celui-ci n’est pas parvenu à destination.
Dans un cas idéal, on devrait espérer 0, ce qui est loin d’être mon cas.
Je ne suis toutefois pas surpris, mais il me faut maintenant analyser pour vérifier que la cause est bien celle que j’avais anticipée : une limitation par la CPU de mon hyperviseur.
Mais avant, juste pour le fun, une vue de ma supervision de mon lien internet (patte WAN de mon parefeu), pendant le même test iperf que précédemment, mais sur une durée de 15 minutes:
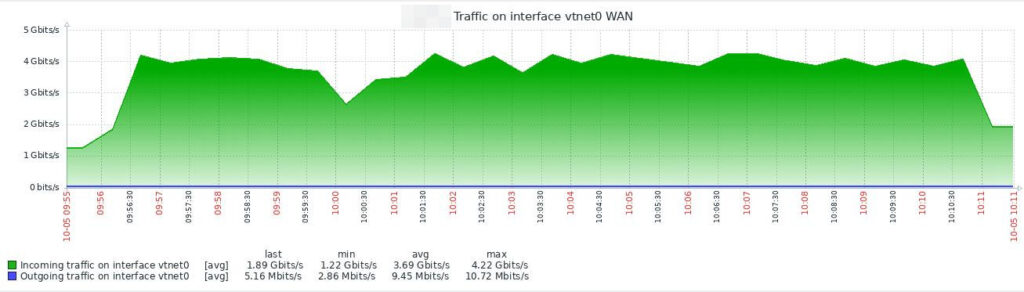
Je pense que les fluctuations sont dues à la fois à la charge du serveur distant, du réseau internet, et surtout à la disponibilité de la CPU de mon hyperviseur, qui n’a pas que ça à faire : le creux que l’on voit d’ailleurs entre 10h et 10h01 est apparu alors que j’étais en train de me balader dans ma supervision, elle-même dans une VM exécutée par le même hyperviseur.
Pourquoi je ne remplis pas le tuyau de 8Gbps
La première crainte à écarter est au niveau du câblage de la maison. En effet, le lien à 10 Gbps entre mon switch opérateur (sur lequel il y a la freebox) et mon switch de coeur de réseau passe sur un câble cuivre, cat 6a, d’une vingtaine de mètres de long. Je n’étais pas à l’abri d’un problème physique dessus (câble abîmé pendant le tirage, mauvais câblage des noyaux RJ45, problèmes de jarretière, etc…). Pour m’assurer que tout va bien ici, j’ai donc surveiller les statistiques de mes commutateurs pendant un trafic à haut débit.
Sur mon switch opérateur:
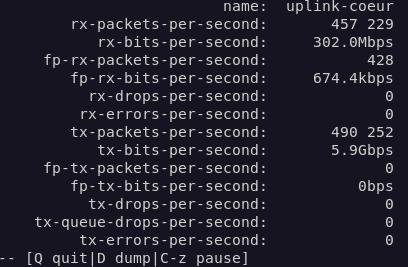
Sur mon switch de coeur de réseau:
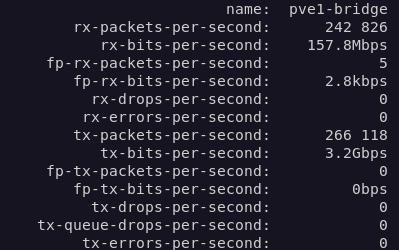
Dans les deux cas, on constate qu’il n’y a aucune erreur de transmission (tx-errors à 0) ou de réception (rx-errors à 0) sur les interfaces concernées. La liaison est donc physiquement bonne.
Par ailleurs, j’ai voulu jouer avec le flow control : il est actif par défaut sur le bridge linux de mon hyperviseur, sur les interfaces virtuelles de mon parefeu, et je l’ai activé sur les interfaces de mes commutateurs : je n’ai vu aucune différence. Je ne sais pas si il a un quelconque effet, ou si le fait de ne pas avoir pu l’activer sur toute la chaîne le rend inutile (je ne sais pas l’activer sur la freebox), mais quoi qu’il en soit je n’ai constaté aucun rejet de paquets (rx-drops et tx-drops), ce qui montre qu’il n’y a eu aucune saturation de tampon d’interface sur mes switchs.
Le « problème » n’est pas là.
Bon, j’avais déjà ma petite idée, comme exposé plusieurs fois auparavant, donc allons droit au but :
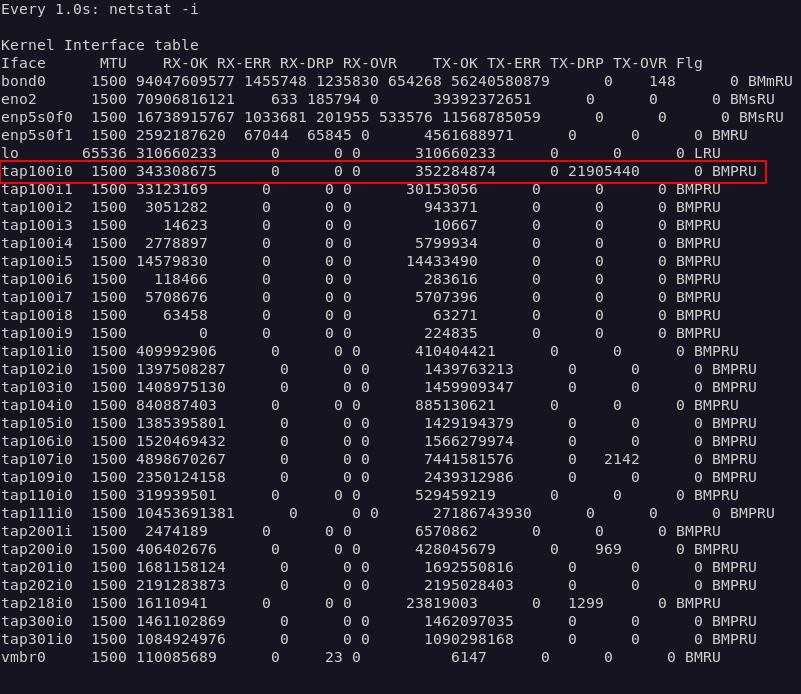
Le coupable est là : je l’ai mis en évidence sur la copie écran ci-dessus : ce sont les statistiques du bridge linux qui connecte au réseau mes VMs. L’interface mise en évidence est la patte WAN de mon parefeu virtuel. On y constate que la colonne TX-DRP, qui comptabilise le nombre de paquets transmis par le bridge à l’interface réseau de la VM et rejetés par celle-ci montre un chiffre énorme : cela traduit le fait que la VM n’est pas en capacité de traiter la quantité de données qui lui parvient, comme je l’avais anticipé. Voilà pourquoi je ne parvient qu’à utiliser à peine 50% de la bande passante descendante de ma freebox.
Pour améliorer ça, je n’ai pas beaucoup de solutions : si le driver virtio pour freeBSD permettait d’exploiter les fonctionnalités de déchargement hardware de ma carte réseau, je pourrais peut-être gagner quelques pourcents.
Mais la vraie solution serait d’avoir des hyperviseurs avec une CPU beaucoup plus puissante, ce qui n’est pas à l’ordre du jour.
Objectif 2 : booster les flux dans mon cluster proxmox
Là, on lâche l’affaire avec des speedtest et autres iperf, pour rentrer dans la vraie vie.
Le temps de migration d’une machine virtuelle d’un hyperviseur à l’autre, peut dépendre, suivant le contexte, à 100% de la vitesse du lien réseau dans le cluster. C’est le cas si la VM est stockée dans un emplacement partagé entre les serveurs (un export NFS par exemple). Dans ce cas, la migration consistera principalement en la recopie de la RAM de la VM d’un serveur à l’autre; et de RAM à RAM, on sature normalement facilement un lien 10Gbps.
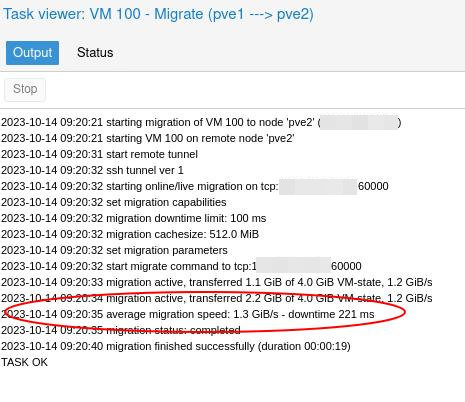 Et c’est bien le cas. Ici, j’ai effectué la migration de mon parefeu, depuis mon hyperviseur 1 vers mon hyperviseur 2. Le disque virtuel de cette VM étant sur un stockage partagé entre les deux serveurs.
Et c’est bien le cas. Ici, j’ai effectué la migration de mon parefeu, depuis mon hyperviseur 1 vers mon hyperviseur 2. Le disque virtuel de cette VM étant sur un stockage partagé entre les deux serveurs.
La RAM de 4Go a été copiée à 10Gbps en à peine plus d’une seconde entre mes deux serveurs, et il a fallu au total 19 secondes pour déplacer la VM, à chaud.
Et ça c’est bien. Très bien même pour une petite infra domestique.
Mais ce cas ne correspond pas exactement à la réalité de mon infra : en effet, je n’utilise que très peu le stockage partagé entre mes deux hyperviseurs. Celui-ci est assuré par mon mininas, qui est une machine de faible puissance et n’ayant qu’une interface 1 Gbps. Les performances de stockage sont donc assez faibles ici, et je n’utilise en général ce stockage que pour mes machines de lab.
Toutes mes VMs de prod sont en réalité stockées dans les volumes RAID SSD locaux des mes hyperviseurs, ce qui implique qu’un déplacement d’une VM d’un hyperviseur à l’autre consistera en un déplacement des disques virtuels de la VM en plus de sa RAM. Et là, plus question de faire bouger uniquement de la donnée de RAM à RAM.
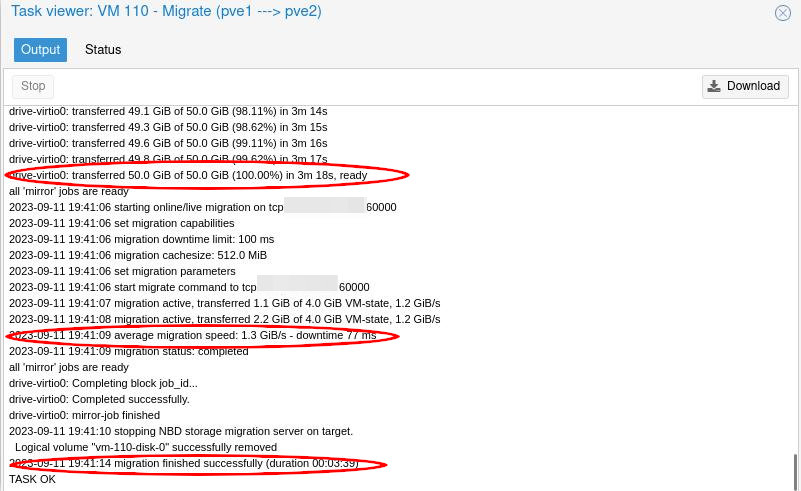
Et effectivement, c’est un peu moins badass : il a fallut 3m18s pour migrer le disque de 50Go de la VM déplacée, soit une vitesse moyenne d’un peu moins de 260 Mo/s. Ça correspond à peu près aux performances des volumes RAID de SSD SATA de mes hyperviseurs.
La recopie de la RAM quant à elle, s’est faite à 1 Go/s, ce qui confirme le résultat de la première migration, et il aura fallu au total 3 min 39 s pour migrer cette VM d’un hyperviseur à l’autre, ce qui me remplit de joie.
Je précise toutefois que mon cluster proxmox a été configuré pour ne pas chiffrer les données en cours de migration : j’assume ça en arguant du fait que ces flux sont isolés dans un vlan qui ne sort pas de mon switch de cœur de réseau. Ça se définit en ajoutant la directive suivante:
migration: type=insecure
Dans le fichier /etc/pve/datacenter.cfg .
En adoptant ce paramètre, je souhaitais m’assurer de maximiser les performances de migration.
Conclusion(s)
Même si je ne suis pas en capacité de consommer les 8Gbps offerts par ma connexion internet, je reste relativement satisfait d’en atteindre à peu près la moitié, sachant qu’en réel, je ne m’attend pas à voir très souvent de tels débits utilisés.
Les flux de mon cluster proxmox profitent largement du 10Gbps, et pour une installation domestique, je trouve que je commence à avoir du lourd.
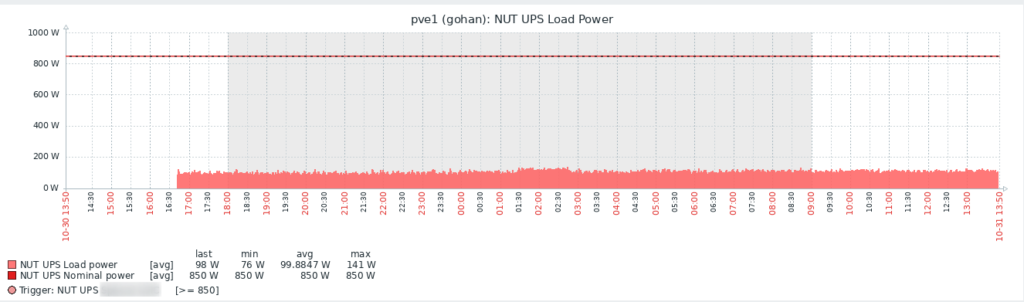
La consommation de ma baie a bel et bien augmenté, d’une vingtaine de Watts, pour tourner en moyenne à 100W, ce qui tout compte fait reste contenu.
o/